导读:本文将介绍网易基于 Apache iceberg 构建的实时湖仓一体系统——Arctic。
主要包括以下几大部分:
.当前业务的挑战:Lambda 架构下流与批割裂带来的问题
.Arctic功能特性:网易 Arctic 基于 iceberg 构建的湖仓一体系统
.业务实践:Arctic 在网易内外的实践
.未来规划
01
当前业务的挑战
1. Lambda 架构下流与批割裂带来的问题
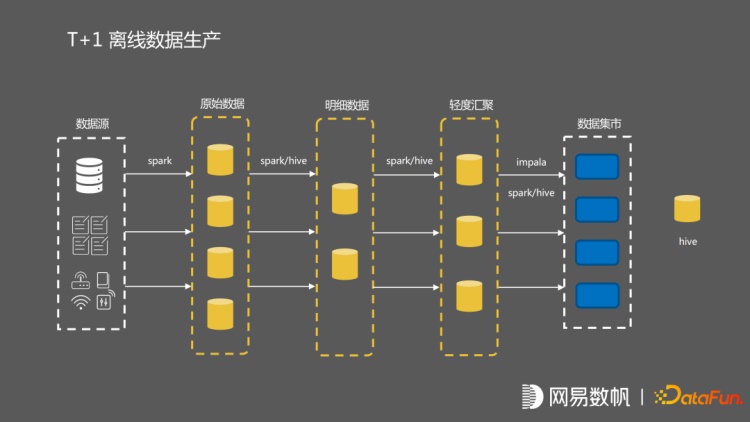
我们目前的业务基本上都是流批一体的,采用 Lambda 架构。上图展示的是一个纯 T的业务的生产数据流。它对应的是 T+1 的离线数据生产。我们在离线的数据生产上,初步引入了一些实时化,引入了一个消息队列,并把 CDC 数据和一些 log 数据引入到了消息队列中。
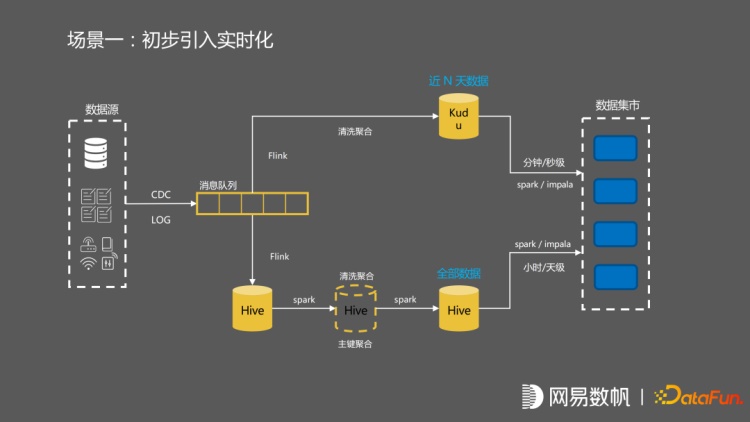
离线流程保持不变的情况下,用 Flink 去做一些清洗聚合,最后数据进入到 kudu当中。在数据集市中,对两边 hive 的数据和 kudu 中的数据进行合并。kudu 这边流的数据,有分钟级别的延迟。hive 这边是一个小时级别或者天级别的数据流,最终在数据集市中做聚合。
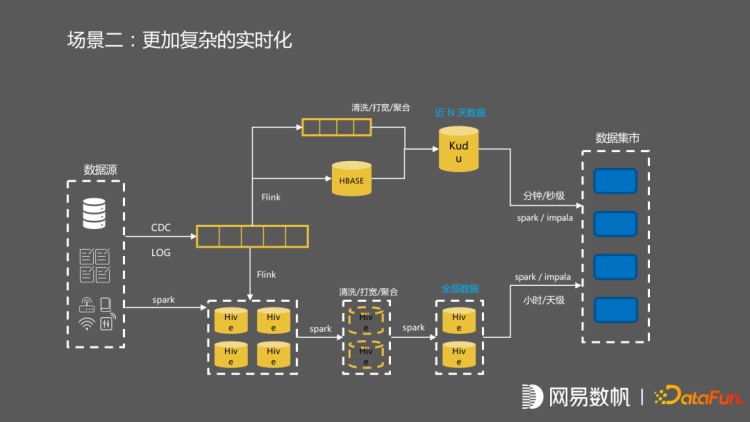
后来我们引入了更复杂的逻辑。首先包括一些清洗打宽聚合的逻辑,一些 Flink 任务开始去往 Hbase 里面生成维表数据,然后在流这边先做一个聚合之后才落入 kudu 当中,最后在数据集市再把流和批去做整合。
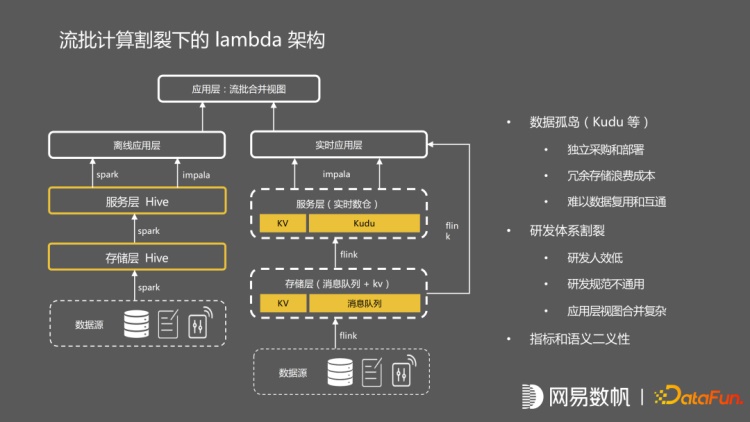
这是一个很典型的 Lambda 架构,流与批的流程是割裂的。这种割裂的 Lambda 架构,最大的问题就是数据孤岛的问题,因为有大量的流的数据存在 kudu 当中,kudu 是一个独立部署的架构,无法利用 hadoop 的整套生态体系,离线的数据也没办法复用,其次是研发体系上流和批处理完全是割裂的,人效很低,并且无法统一指标和语义。
02
Arctic 功能特性
1. Arctic 的定位
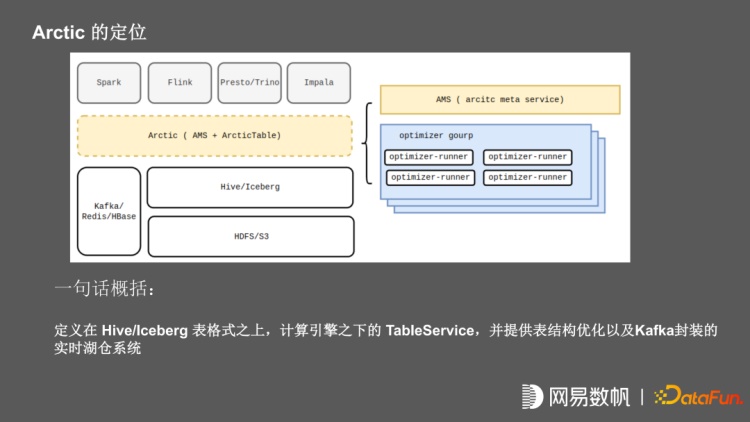
基于以上现状,我们研发了 Arctic 产品,它是基于 Iceberg 去构建湖仓一体的系统。其定位是在 hive 和 Iceberg 之上,在计算引擎之下的一个 TableService, 并提供表结构优化以及 Kafka 以及 redis, Hbase 等 KV 存储封装的实时湖仓系统。
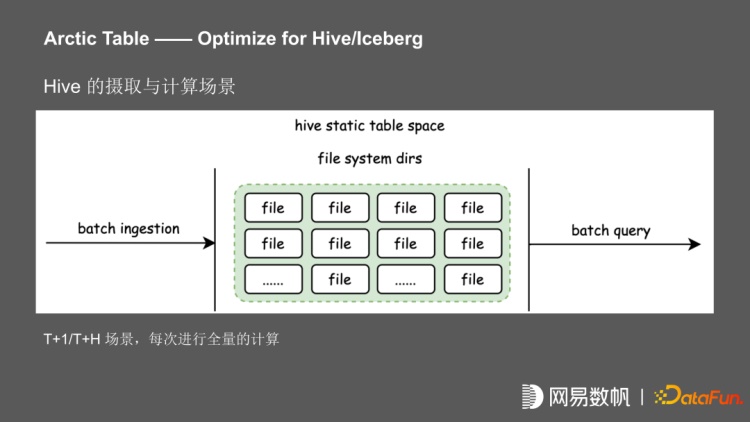
上图是一个 T+1 的 hive 计算场景。一个批的数据,进行了 T+1 或者 T+H 的摄取,再进行批的计算,每次都进行了全量的摄取或计算,在此基础上我们引入了 Iceberg 和 Deltalake。
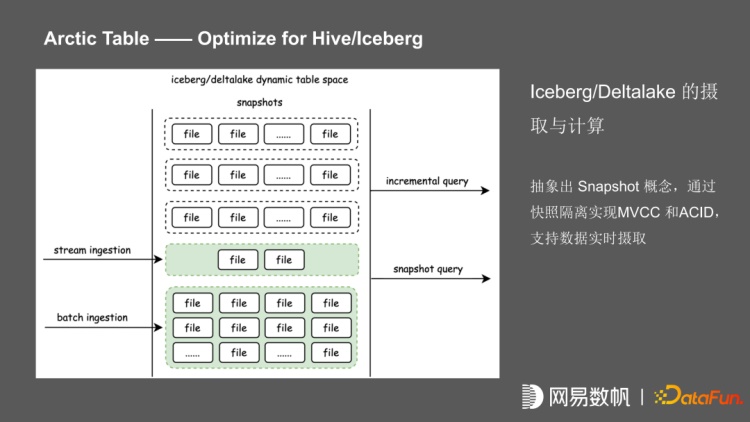
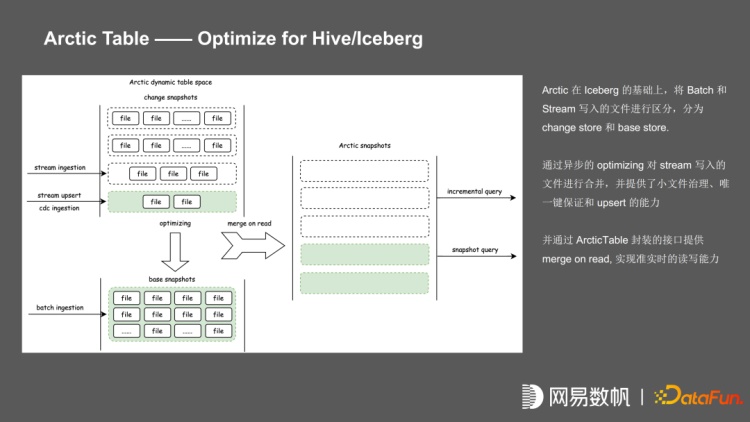
Iceberg 通过快照的隔离实现了 MVCC 和 ACID, 在基于 MVCC 和 ACID 的情况下,可以支持数据实时摄取,也支持准实时的 incremental query。在 Iceberg 的基础上,Arctic 进一步进行了区分,把 batch 数据和 stream 的数据写入的文件进行分区,分为 change store 和 base store。通过异步的 optimizing 对 stream 写入的文件进行合并,并提供了小文件治理、唯一键保证和 upsert 的能力,通过 ArcticTable 封装的接口提供 merge on read,实现准实时的读写能力。
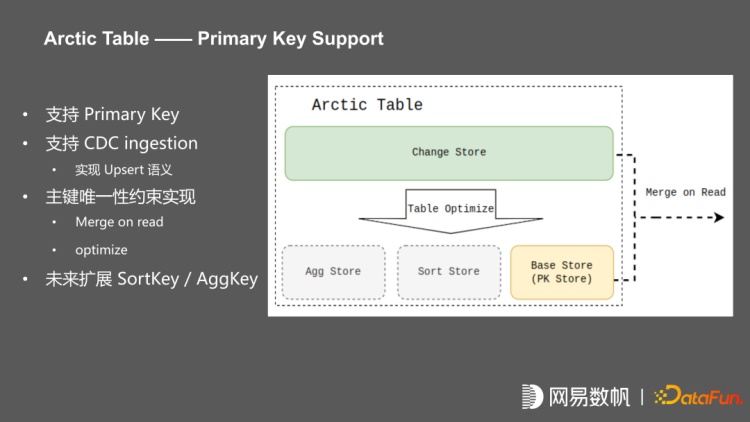
我们在架构上把 Arctic Table 划分为多个 Table store,流写入叫 Change store,批写入叫 Base store,并通过 table optimize 实现 primary key 的唯一键约束。primary key 提供的是 upsert 语义,包括 CDC ingestion,Batch Insert 的时候可以实现基于组件的更新,并通过 merge on read 保证唯一性约束。每个 table store 的实现都是一个 iceberg 表,未来在提供 base store 之外,还会提供 SortKey、AggKey。
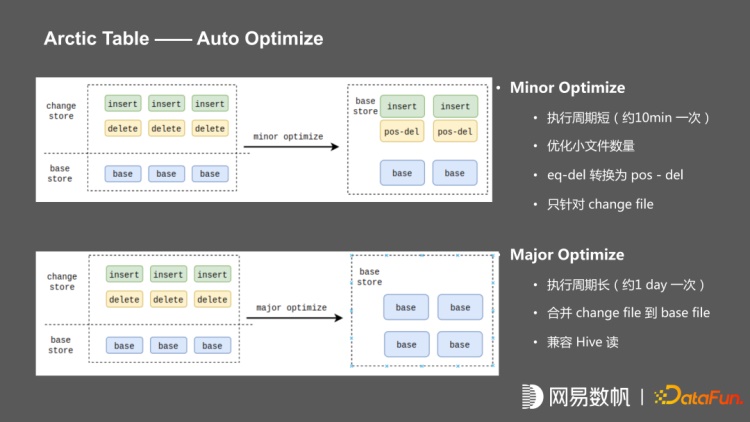
我们对 Arctic Table 做了两种 Optimize,一种是短周期的 Minor Optimize,大约 5 到 10分钟执行一次,主要提供小文件的治理,把写入 change store 中间的 equal delete 转换 pos-delete。另外一种是长周期的 Major Optimize,大约 1 天执行一次,将 insert file 和 change file 合并到 base file,当合并的 major optimize 执行完成之后,就只有 base 表,base 文件与 hive 格式完全兼容。
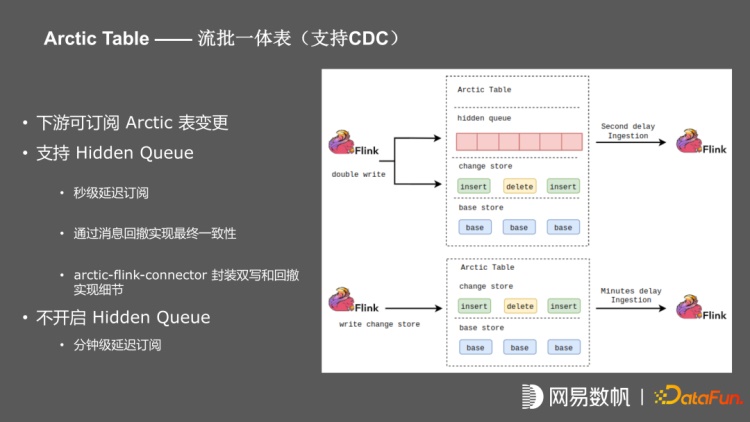
为了增强流处理下的应用场景,进行了 hidden queue 封装,在 Arctic table 内部封装kafka,对实时性要求高的上游任务进行双写,即往 change store 写同时也写入 hidden queue,下游直接从 kafka 消费,以此达到秒级甚至毫秒级的 CDC。如果不开启 hidden queue,上游只写 change store,下游利用 iceberg incremental poll 实现分钟级别订阅,整个双写过程通过 Arctic-Flink-connector 进行封装。
在双写情况下会遇到一致性问题,比如上游 Flink 任务在双写的时候,要保证毫秒级和秒级延迟,需要先写入 kafka,再写入 iceberg 文件,可能会在写入的时候,任务发生故障,导致 iceberg 文件并没有提交,而下游已经消费了未提交的数据,如果上游任务做了 failover 会导致部分数据重发,下游重复消费。
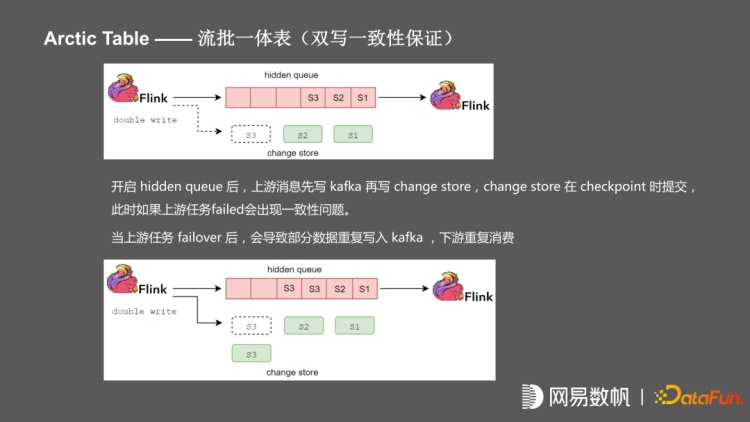
为解决这个问题,arctic 在双写的时候用回撤方式对消息提供了最终一致性的保证,所有写入 Kafka 的消息均进行了一次封装,每一个消息带上上游 writer 对应的 state 周期,即当前的 checkpoint 的 index。在下游任务发生 failover 之后,会根据 checkpoint 恢复,先发出 Flip 消息,下游任务收到 Flip 消息之后,会自动的从 Kafka 中扫描找到对应的需要回撤的消息并进行 retract 操作,整个流程在 Arctic-flink-connector 封装,屏蔽业务层面双写带来的一致性问题,业务层面只需要将 Arctic 当成流表使用。
同时为了支持将 Arctic 当维表使用,实现了一个 hidden 的 index,内部封装了 Hbase或 Redis,支持在上游写入实现双写,数据写入 redis 或 HBase,下游不需要关心实现细节,将 Arctic 当成维表使用,但这种情况下,目前没有比较好的办法解决一致性,未来会实现 flink1.12 中提出来的时态表 temporal join,无需依赖外部 KV。
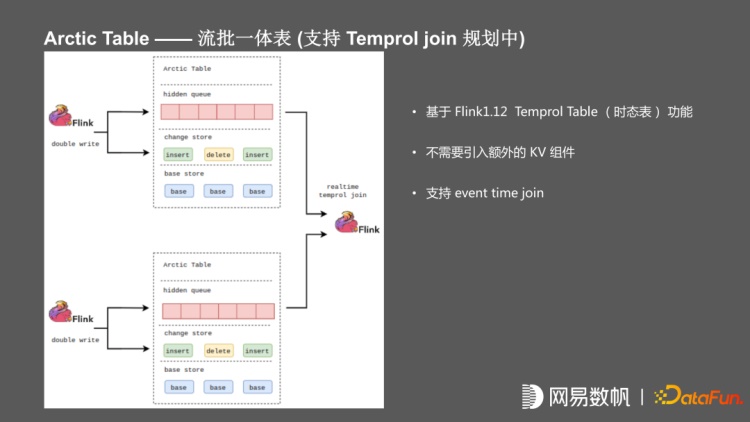
在使用时态表(temprol table)的情况下,流表、维表都写入 kafka,下游做 left join 的时候已经把数据缓存在 flink 的 state,不需要引入额外的 KV 组件,也不存在一致性问题,且能支持 event time join,当前方案处于规划中。
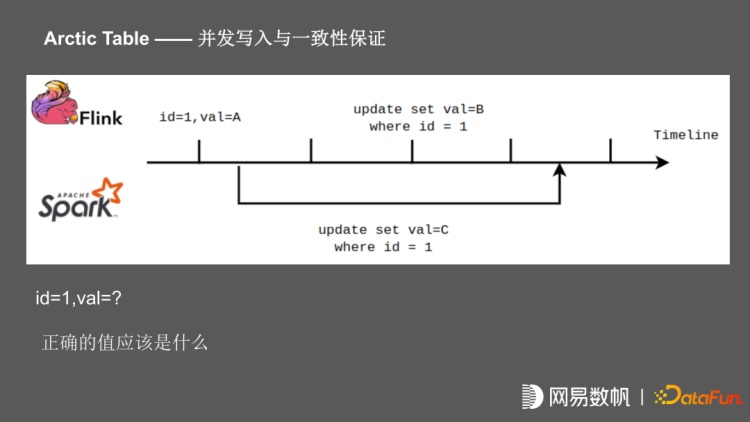
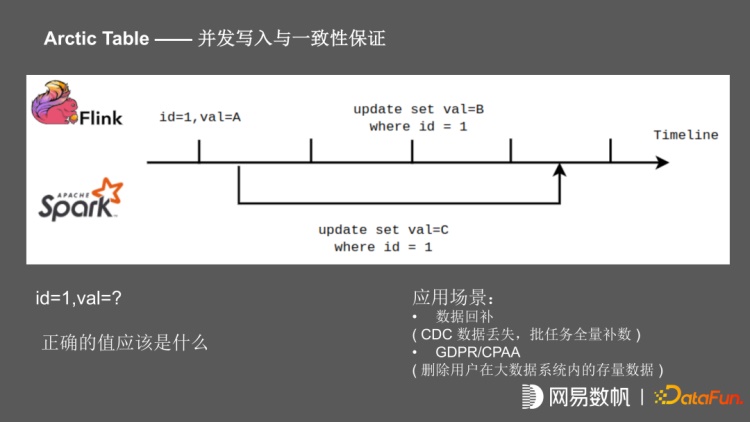
为了支持流、批的同时,写一张 Arctic 表,在并发写入时涉及一致性问题。比如在这个场景中,在某个时间点的记录 ID =1,value=A,这个时候开始 spark 任务,将 value 更新为 C, flink 任务启动之后一直在写,在后面 commit 的时候把值 value 更新为 B,在任务结束之后该记录值应该是多少?由于 Iceberg 在 commit 的时候做 ACID 的保证,且 Flink 任务是先 commit 的,Spark 任务是后 commit 的,在这个时间点,它的 value 应该是 C。但是我们按照传统数据库的视角来看,spark 任务在开启时 value 已经确定,这时 Flink 任务进行更新,记录已经被锁住,当 spark 任务进行 commit 之后,记录才能够被更新,在数据库的视角来看,在这个时间点该记录 value 应该为 B。
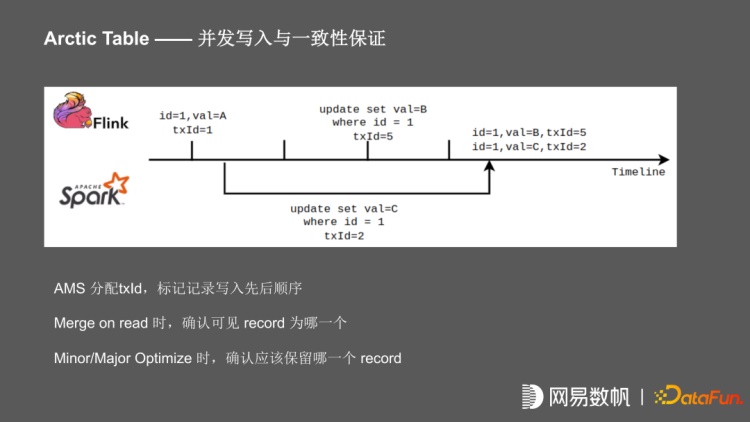
有两种比较常见的业务场景,一种是数据回补的场景,比如 CDC 任务发生故障,在重跑时发现 CDC 数据已经有一些丢失,这时需要批任务进行数据全量回补。还有一种场景,在有 GDPR/CPAA 方案时,要求支持用户关闭推荐,删除大数据系统内用户的存量数据;这种流式在不停的写入的情况下,需要进行级更新。我们的做法就是引入了一个 txId 的概念,对于每一个 Flink 任务,每个 check point 周期开始时,向 Arctic 申请 txID,在写入的时把 txID 与批文件、对应的 txId 一起写入。对于 spark 任务,在 plan 时申请 txId ,最终在写入时,把 txID 与文件信息一起写入。当读取任务进行 merge on read 时,根据具体的 txId 的前后顺序,决定最终读哪一个 record;包括 Minor/Major Optimize 时也是根据 txId 决定最终保留的 record。
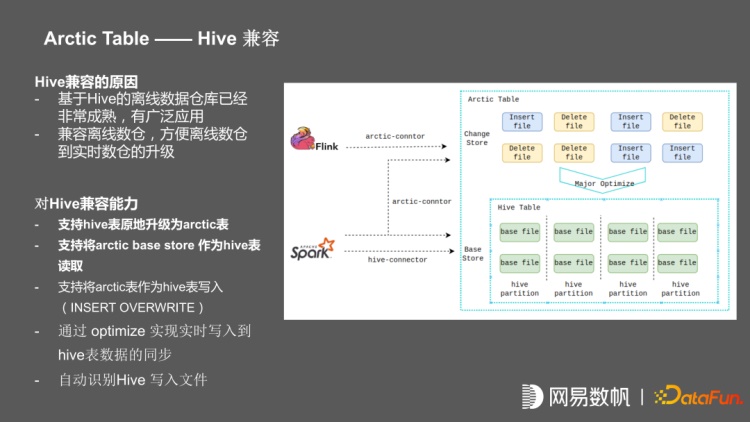
推广的过程中,在内部首先推广 iceberg,但是我们在推广流批一体的过程中,发现已经有很完善的 hive 生态;包括基于 hive 构建的一整套大数据的方法论,和围绕 hive 的中台组件,我们发现几乎不太可能离开 hive 。我们后来就对基座重新做了规划,在支持 iceberg 当作基座的情况下,又支持直接将 hive 作为基座。在这种情况下,支持直接将 hive 原地升级为 arctic 表,原地升级的意思是会保留 hive 表,并且保留原有 hive 表上所有任务。对原有的 hive 表的读写任务是没有任何侵入的。支持将 hive 表升级成 arctic 表之后,支持将 arctic base store 作为 hive 表进行读写,支持通过 Flink 任务往 arctic 表上写,通过我们的 optimize 往 hive 表同步。使得在离线场景中不用做任何改动的情况下,增加离线表的实时能力。
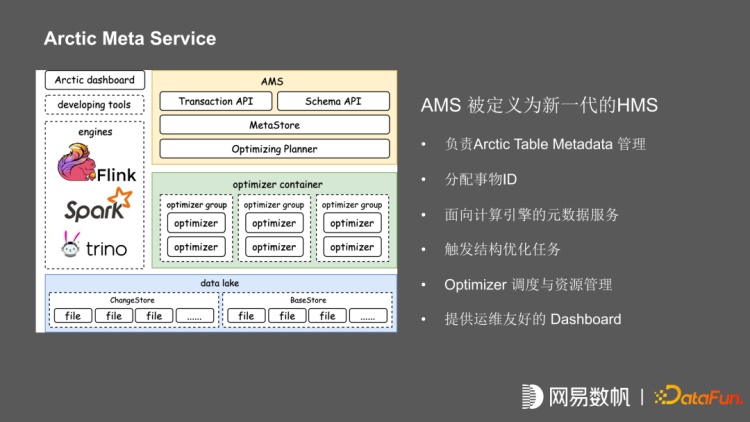
Arctic meta service,简称AMS,它的定位是未来的 HMS。负责 Arctic Table Metadata 的管理,分配事物 ID,提供面向数据引擎的元数据服务。在 AMS 内部可以进行多个 HMS 管理,AMS 还负责触发表结构优化任务,优化任务包含基于时间的触发,基于文件大小,小文件碎片的评估的自动触发;以及优化任务的调度与资源管理,同时提供运维友好的 Dashboard。
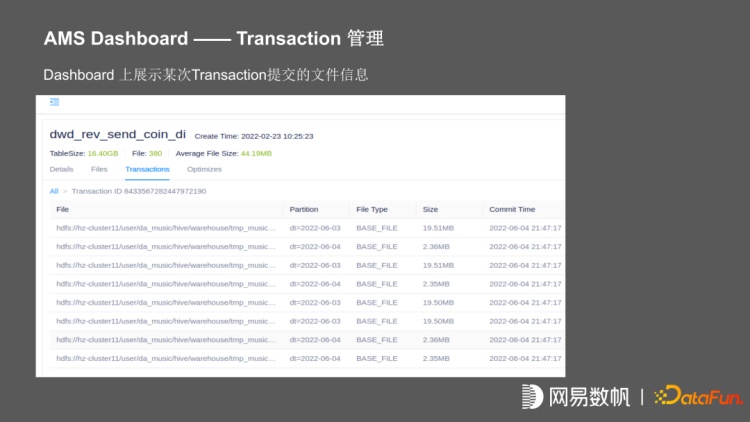
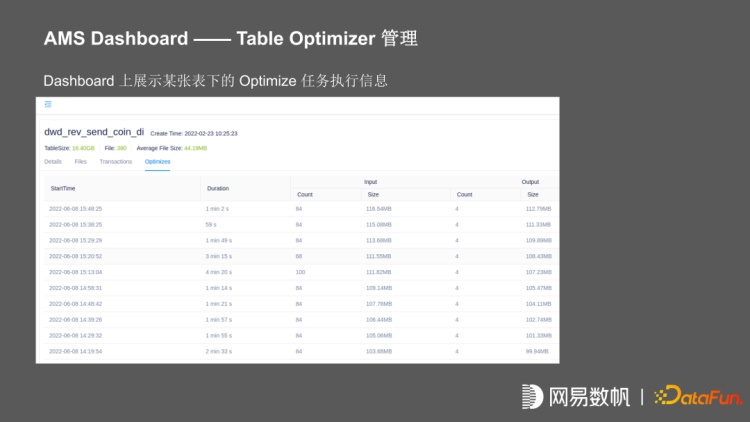
上图为 dashboard 展示的某张表在某一个 transaction 中,所提交的所有文件信息,还有在 optimize 的执行信息,我们可以看到它在某一次 optimize 执行之后,将 84 个文件合并成 4 个。

我们在立项的时候,对目前的数据湖产品,以及数据仓产品进行对比;其中与 Arctic 定位最相似的是 Hudi。Arctic 与 Hudi 的区别在于,Hudi目前对于多写的场景支持的不是很好。它的 CDC 目前还是分钟级的,并不是秒级;而且以它当维表的情况下,用起来不是太友好。另外,Arctic 和 Hudi 的底层不一样,arctic选用更面向未来的,在未来可能会替代 hive 的 iceberg 作为底层。Kudu 的主要痛点是存算不分离,无法利用 HDFS 的资源,存在数据孤岛,无法实现不同层数据串联,以及存在性能问题。
Arctic 的优势首先是基于 iceberg,兼容 iceberg 所有功能,同时对 hive 兼容性好,在短时间业务升级阻力更低;支持动态调度自动触发合并任务,提供分钟级别延迟数仓的 merge on read;在开启 hidden on queue 的情况下,提供流批一体的功能包括秒级实时订阅和实时 join;还提供方便管理的运维平台,方便业务更快的上手。
03
实践案例
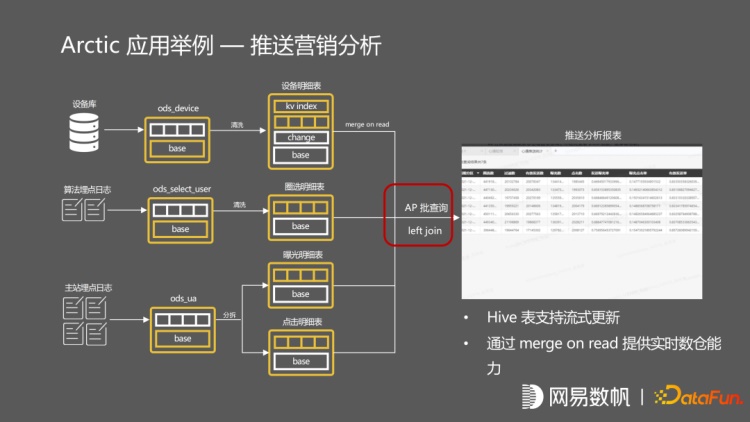
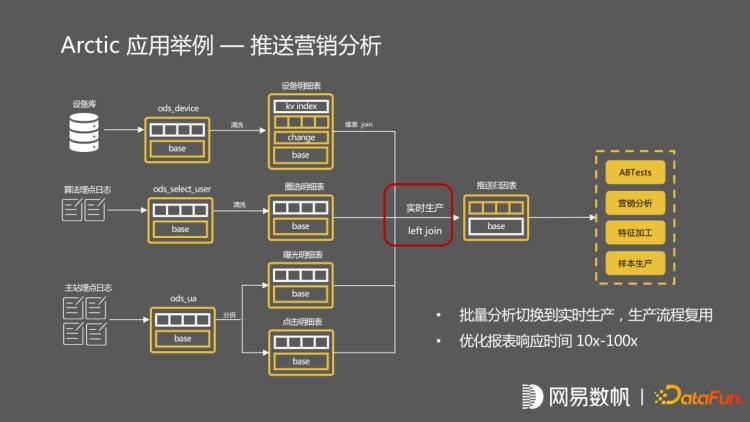
这是在网易云音乐的应用案例,它是一个推送系统分析,有两张主站埋点的 log 日志,及算法埋点的 log 日志。设备库是一个 mysql 维表同步。分析师想要知道推送的效果,需要通过报表进行查询。它是通过一个 IP 的查询来回的 join 这些表,走的批的流程,跟原来的批计算流程完全一致。如果分析师在报表分析之后,去做算法上的优化。可以在架构不发生变化的情况下,立刻推送到面向流的应用,同样是个 left join,但是它走的流程全部是这种流的生产路径,数据全部经过 kafka 做来回的校验,最终推送到归因表中,最后由数据应用去使用流计算出来的结果数据,整个生产链路包括数据存储,指标也不存在二义性,只有一份的数据存储,任务等实现百分百复用。
04
未来规划

未来的规划主要包括:
.会更加专注于流批一体的场景,提供 doris 一样的 RollUp 聚合视图, 提供 sort key 的支持,支持简单的 sort key 排序或者 z-order 的排序,以及部分列的 stream upsert,支持 temperol join。
.在中台的整合方面,会继续去追踪到任务提交信息,后续会持续追踪任务的血缘和数据血缘,并且在 dashboard 上提供简单的自助查询。
.在安全体系方面,未来会支持更加开放的权限插件,支持 ranger 对接。
.未来会支持更多的底层数据湖存储,如 S3、OSS 等。
图片来源:网易数帆
 金鹰集团5G+工业互联网应用场景
金鹰集团5G+工业互联网应用场景









